Aws Glue Catalog
Aws Glue Catalog - The aws glue data catalog is a centralized metadata repository for all your data assets across various data sources. You can use this tutorial to create your first aws glue data catalog, which uses an amazon s3 bucket as your data source. The aws glue data catalog is your persistent technical metadata store in the aws cloud. The aws glue data catalog is central repository that stores the metadata information about your data. In simple terms, a data catalog is just like a data dictionary that keeps the details like. Aws glue catalog is a centralized repository that stores data metadata and provides a unified interface for users to query, analyze, and search. The data catalog is part of aws glue, a serverless data integration service that helps you discover, prepare, move, and integrate data. Key benefits of using aws glue. Learn how to get started with aws glue to automate etl tasks. After completing these steps, you will have successfully used an amazon s3 bucket as the data source to populate the aws. Each aws account has one aws glue data catalog per aws region. What is aws glue catalog? It provides a unified interface to store and query information about data. In this post, we discuss how to use aws glue data catalog to simplify the process for adding data descriptions and allow data analysts to access, search, and discover. Populate the aws glue data catalog with metadata tables from data stores. Aws glue is a serverless service that makes data integration simpler, faster, and cheaper. After completing these steps, you will have successfully used an amazon s3 bucket as the data source to populate the aws. Set up glue, create a crawler, catalog data, and run jobs to convert csv files to parquet. In this tutorial, you'll do the following using the aws glue console: The aws glue data catalog is a centralized metadata repository for all your data assets across various data sources. The aws glue data catalog is a centralized metadata repository for all your data assets across various data sources. You can discover and connect to more than 100 diverse data sources, manage your data in a. The aws glue data catalog is central repository that stores the metadata information about your data. In simple terms, a data catalog is just. In addition to being a data. It acts as an index to the location, schema, and runtime metrics of. Key benefits of using aws glue. You can visually create, run, and monitor extract,. The data catalog is part of aws glue, a serverless data integration service that helps you discover, prepare, move, and integrate data. It acts as an index to the location, schema, and runtime metrics of. In this tutorial, you'll do the following using the aws glue console: The aws glue data catalog supports automatic table optimization of apache iceberg tables, including compaction, snapshots, and orphan data management. Aws glue catalog is a centralized repository that stores data metadata and provides a unified. You can use this tutorial to create your first aws glue data catalog, which uses an amazon s3 bucket as your data source. Populate the aws glue data catalog with metadata tables from data stores. You can visually create, run, and monitor extract,. The data catalog is part of aws glue, a serverless data integration service that helps you discover,. The aws glue data catalog is a powerful tool for managing and analyzing your data in aws. With aws glue, you can discover and connect to more than 70 diverse data sources and manage your data in a centralized data catalog. Populate the aws glue data catalog with metadata tables from data stores. Use this tutorial to create your first. In this tutorial, you'll do the following using the aws glue console: Each aws account has one aws glue data catalog per aws region. The data catalog is part of aws glue, a serverless data integration service that helps you discover, prepare, move, and integrate data. Populate the aws glue data catalog with metadata tables from data stores. The aws. Aws glue catalog is a centralized repository that stores data metadata and provides a unified interface for users to query, analyze, and search. Populate the aws glue data catalog with metadata tables from data stores. After completing these steps, you will have successfully used an amazon s3 bucket as the data source to populate the aws. The data catalog is. In this tutorial, you'll do the following using the aws glue console: With its automated discovery features, integration with other aws services, and. Each aws account has one aws glue data catalog per aws region. In this post, we discuss how to use aws glue data catalog to simplify the process for adding data descriptions and allow data analysts to. The aws glue data catalog is a powerful tool for managing and analyzing your data in aws. Key benefits of using aws glue. In this post, we discuss how to use aws glue data catalog to simplify the process for adding data descriptions and allow data analysts to access, search, and discover. The aws glue data catalog is central repository. The aws glue data catalog supports automatic table optimization of apache iceberg tables, including compaction, snapshots, and orphan data management. Learn how to get started with aws glue to automate etl tasks. With its automated discovery features, integration with other aws services, and. Populate the aws glue data catalog with metadata tables from data stores. The aws glue data catalog. The aws glue data catalog is a centralized repository that stores metadata about your organization's data sets. After completing these steps, you will have successfully used an amazon s3 bucket as the data source to populate the aws. In simple terms, a data catalog is just like a data dictionary that keeps the details like. Populate the aws glue data catalog with metadata tables from data stores. Each aws account has one aws glue data catalog per aws region. Set up glue, create a crawler, catalog data, and run jobs to convert csv files to parquet. The aws glue data catalog is a powerful tool for managing and analyzing your data in aws. In addition to being a data. The aws glue data catalog supports automatic table optimization of apache iceberg tables, including compaction, snapshots, and orphan data management. You can use this tutorial to create your first aws glue data catalog, which uses an amazon s3 bucket as your data source. You can discover and connect to more than 100 diverse data sources, manage your data in a. Aws glue is a serverless service that makes data integration simpler, faster, and cheaper. Aws glue catalog is a centralized repository that stores data metadata and provides a unified interface for users to query, analyze, and search. With its automated discovery features, integration with other aws services, and. What is aws glue catalog? With aws glue, you can discover and connect to more than 70 diverse data sources and manage your data in a centralized data catalog.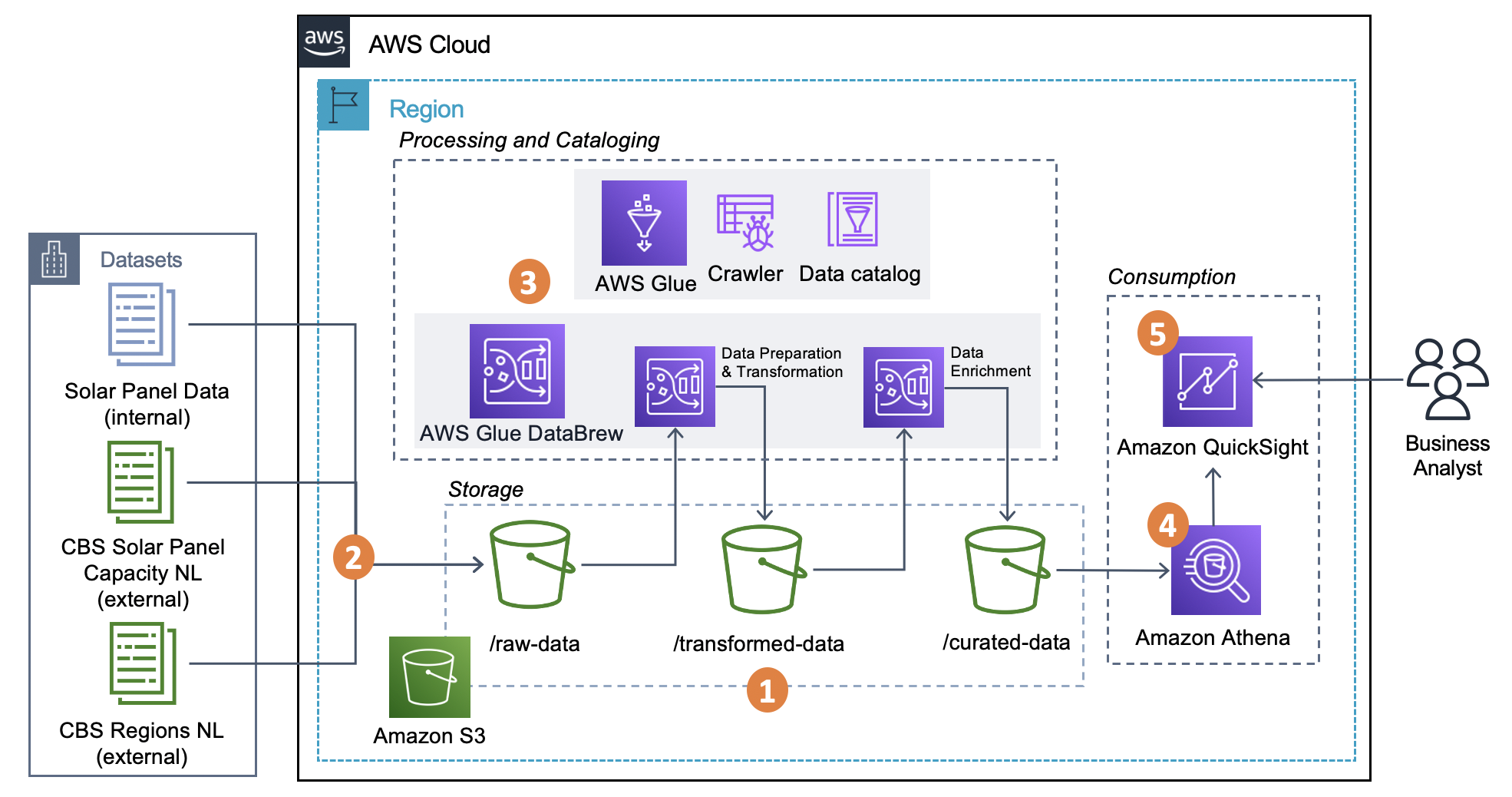
Enrich datasets for descriptive analytics with AWS Glue DataBrew AWS

Build operational metrics for your enterprise AWS Glue Data Catalog at
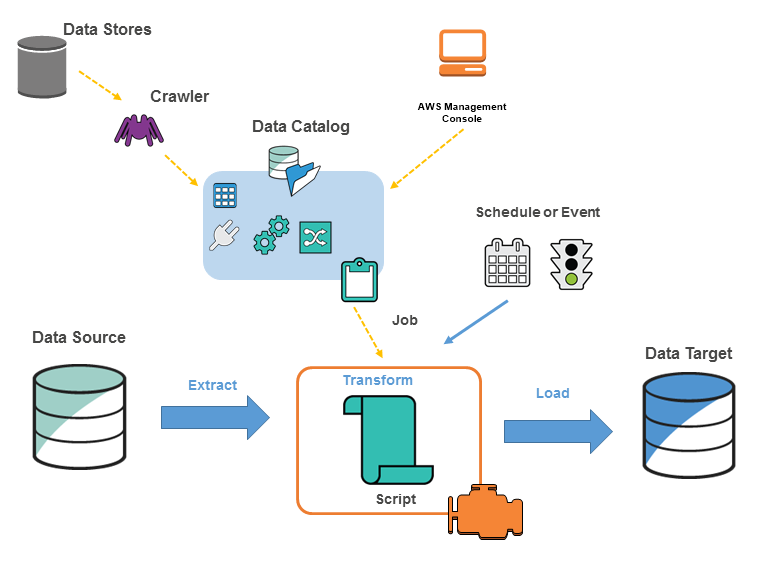
AWS Glue Concepts AWS Glue

Simplify data discovery for business users by adding data descriptions
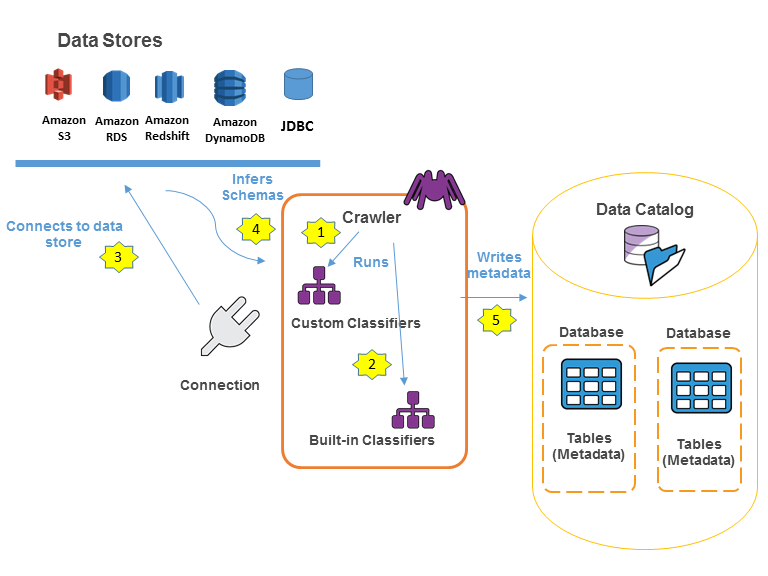
AWS Glue Data Catalog の入力 AWS Glue

AWS Glue Data Catalog as the centralized metastore for Athena & PySpark

Populating the AWS Glue Data Catalog AWS Glue

Getting started with AWS Glue Data Quality from the AWS Glue Data

What is Amazon AWS Glue?

Aws Glue Examples
The Data Catalog Is Part Of Aws Glue, A Serverless Data Integration Service That Helps You Discover, Prepare, Move, And Integrate Data.
Use This Tutorial To Create Your First Aws Glue Data Catalog, Which Uses An Amazon S3 Bucket As Your Data Source.
Key Benefits Of Using Aws Glue.
The Aws Glue Data Catalog Is Central Repository That Stores The Metadata Information About Your Data.
Related Post: